Walking for the Loneliness
· 3 min read

"We are all walking for the loneliness."
In the blink of an eye, I've made it through undergraduate studies. Looking back, this blog has also been around for 4 years.
In 2021, I got into CTF, and after tsctf-j 2021, I followed suit and built my own blog. After 4 years of evolution, the blog has become what it is today. Writing and deleting, deleting and writing, I haven't written many technical blogs, but there are quite a few narrative ones. Over the 4 years, through picking and choosing blog engines, patching and mending, the blog has changed from WordPress to Hugo, then to others, and finally settled on this messily modified Docusaurus.
The blog's domain has also changed repeatedly, from the initial novanoir.dev / novanoir.moe, to later ova.moe, and now to nova.gal, perhaps it will finally settle on this domain (wiping tears).
"Why can’t I do a VM escape?" I suddenly wondered while walking down the street—recalling the old saying: "Anyone who can’t escape a virtual machine is doomed to fail."
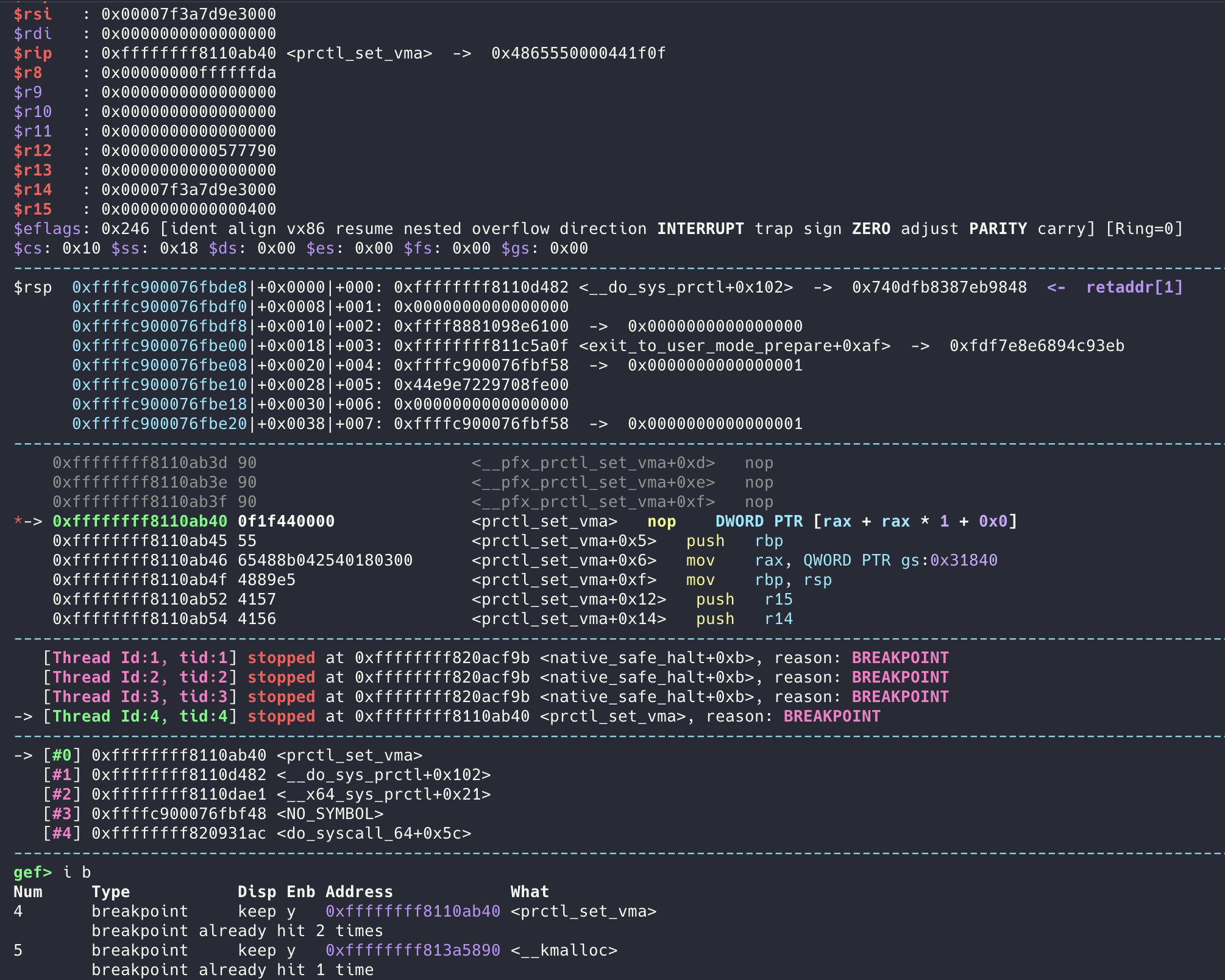
There are many types of VM escapes. Today, let’s tackle the most classic PWN: QEMU escape.
A quick note: this can be used as a heap-spray object. You can spray sizes in the range [kmalloc-8, kmalloc-96], with each system call allocating exactly one object under the GFP_KERNEL flag. The name is readable (though truncated at \0), and you can free it.
I saw this in a paper, but after checking around I found no one in China has written about this struct. Its small size makes it quite useful. You could also use msg (message queues), but those live in cgroup groups and to heap spray you’d need cross-cache techniques, which is cumbersome.
You can see between two syscalls there is only one __kmalloc invocation:
It's been a while since I last posted on the blog. I recently got a Mac and encountered this issue—here’s how to fix it.
In short, macOS Cloud Storage uses "OneDrive - %ORG_NAME%" as the unique identifier when adding OneDrive accounts. This prevents adding multiple identical accounts, which is quite inconvenient for E5 cloud storage free riders like me.
Honestly, I’ve been procrastinating on this because it feels like I’ve already summed up 2024 across various posts (guilty).
But as an annual ritual, let me write it down in a new way.
This was my first time in Japan, and I’m sure there will be many more trips in the future—hence ep.1.
In this episode, I’ll explore Japan from the perspective of an ordinary tourist, following recommendations from XiaoHongShu and other travel apps, focusing on the Kanto and Kansai regions.
Our planning was quite rushed, choosing to fly into Osaka and out of Tokyo. Since it was the busy year-end season, we should probably have gone to Hokkaido. And because my travel companions aren’t anime fans, there was almost no pilgrimage to famous anime spots.
So this travelogue will be a simple, everyday-tourist perspective on Japan, highlighting popular attractions. On future trips, I plan to follow the thread of “culture,” experiencing local life and cuisine more deeply.
I didn’t want to overthink it, so I’ll just write in a stream-of-consciousness style, haha.
"Nothing really changes," I tiptoed out of the hotel room door and moved towards the dark emergency exit. It wasn't until my vision went completely black that I realized I had stopped breathing at some point. I gasped for air, oblivious to the fact that the starry sky had already filled the entire staircase and entered my nostrils.
It feels like being scammed when buying virtual goods is not a one-time thing; I've been scammed by thunder strikes, pig-killing scams, and more...
This article is still under active construction
A few days ago, I was chatting with my junior @奇怪的轩轩 about the issue of "not having any truly original content." Thinking it over, I realized I haven't really produced much in the way of original (technical) content—most of my work consists of drawing on and retelling others’ ideas. Its intrinsic value is limited and it’s not very irreplaceable.
Coincidentally, I just started my undergraduate thesis proposal. Although my thesis topic is fairly light, considering all the related work to come, I decided to take it seriously.
Thus, this new series was born. The NoPaper series will be akin to a literature review: sharing, translating, and summarizing papers in a specific field from classic works up to the SOTA. I don’t know exactly how it will turn out, but at least it should match the daily/weekly rhythm of something like G.O.S.S.I.P :D
Anyway, for the first installment, I’ve chosen to start with Sanitizers. After all, it will serve as Chapter 1 of my thesis