After fooling around for a month, finally starting to dive into PWN.
Dynamic Linking Mechanism in Linux
Dynamic Linking vs Static Linking
When building an executable1, there are usually two stages: compilation and linking. Dynamic linking and static linking are two different mechanisms used in the linking stage.
Static Linking
Involves linking multiple object files generated from individual source files (each .c file generates a .o file) to create an executable. This process is known as static linking.
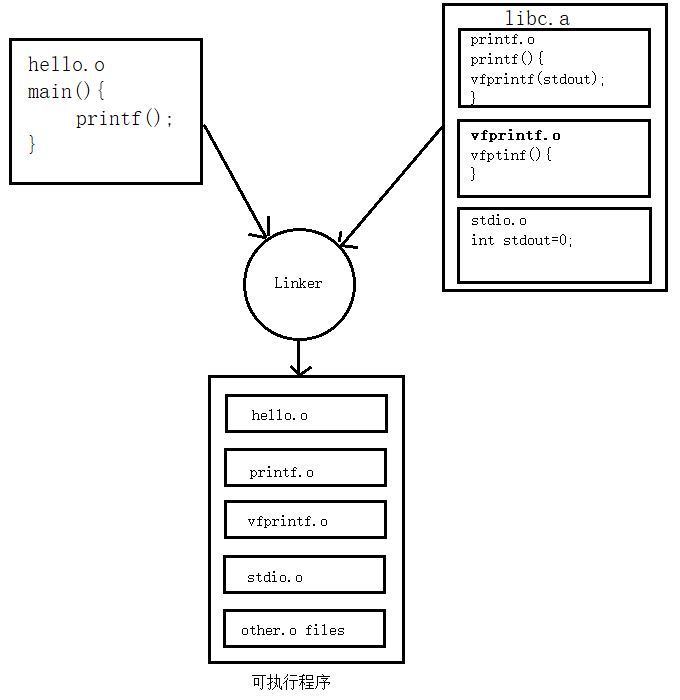
After linking, the content of these static libraries2 is integrated into the executable file, or loaded into the address space of the executable file with static memory offsets determined during linking. This typically results in executable files created by static linking being larger compared to those created by dynamic linking.
When a program (executable file or library) is loaded into memory, static variables are stored in the program's address space in the data segment (initialized) or bss segment (uninitialized).
Advantages
- Avoids dependency issues
- Allows applications to be included in a single executable file, simplifying distribution and installation
- Faster execution speed
Disadvantages
- Difficult to update and maintain (requires relinking each time there are updates or maintenance, and users need to redownload the entire program for updates)
- Wastes space (each executable file contains copies of the functions it needs)
Dynamic Linking
Dynamic linking mainly addresses the drawbacks of static linking.
The idea behind dynamic linking is to link program modules together to form a complete program only at runtime. During linking, it only marks unreferenced symbols and generates additional code segments (the PLT table) for symbol redirection at runtime. Different systems implement dynamic linking differently, and you can find more information on dynamic linkers under Dynamic Linker on Wikipedia. We will now focus more on dynamic linking in Unix-like Systems.
For a detailed explanation of the dynamic linking process, you can read What is PLT and GOT in Linux dynamic linking (1) — What is PLT and GOT in the references.
Advantages
- Easy to update and maintain
- Saves space
Disadvantages
- Slightly lower runtime performance compared to static linking
GOT & PLT
GOT
Global Offset Table3, maps symbols to their corresponding absolute memory addresses.
PLT
Procedure Linkage Table4, maps functions to their corresponding absolute memory addresses.
The global offset table converts position-independent address calculations to absolute locations.
Similarly, the procedure linkage table converts position-independent function calls to absolute locations.
In brief, the code at the PLT works like this: it jumps to the GOT table to look up the actual address of the function to be executed. If the address needed is not in the .got.plt section, the linker will find the function, fill its address into the .got.plt section, and then jump to execute it.
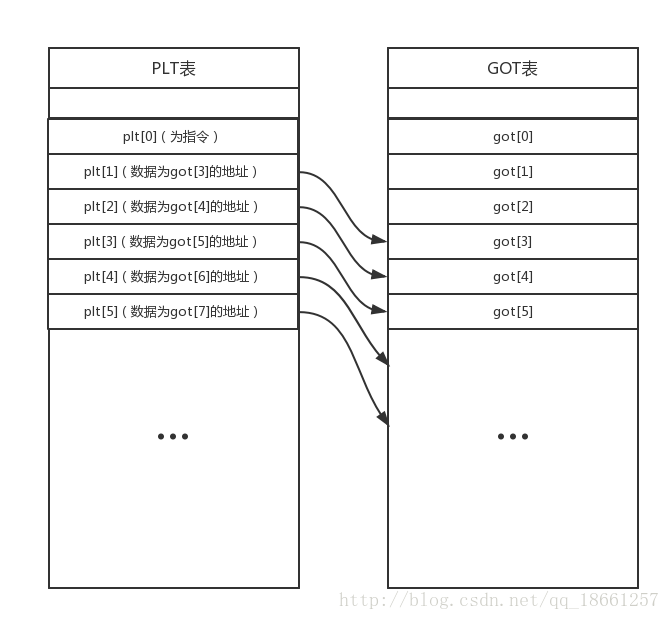
This is a simplified diagram.
When executing function@plt, the program first executes jmp [[email protected]].
Before function is called, [email protected] contains [function@plt+4], meaning that before the function is executed, jmp [[email protected]] actually just jumps to the next line push 0xX.
Here, 0xX represents the index position in the GOT table. For example, if function is plt[1], then its corresponding X is 3, i.e., push 0x3.
It then executes jmp plt[0].
We won't delve into the specifics of plt[0]; just understand that it locates the linker, uses GOT[1] and GOT[2] to store the actual address of the function at the corresponding [email protected], and executes the function to return.
So, when function@plt is executed for the second time, jmp [[email protected]] jumps to the actual address of the function.
This is the theoretical basis for obtaining libc offsets through GOT leaks.
References
What is PLT and GOT in Linux dynamic linking (1) — What is PLT and GOT
In-depth understanding of static linking and dynamic linking
Thorough understanding of GOT and PLT
Detailed explanation of GOT table and PLT table
Footnotes
